320x100
지난 포스팅에서 R 과 R Studio를 설치하는 방법에 대해 알아보았습니다.
R Studio를 설치 완료를 했으면 R로 데이터분석을 하기위해 간단한 문법들을 알아볼 예정입니다.
아직 설치를 하지않으신 분들은 아래 포스팅을 참고하여 설치완료하시길 바랍니다▼▽▼▽▼
R 및 R studio 가장 쉬운 설치방법-[빅데이터,통계-R]
요즘 빅데이터분석 도구로 R 언어를 배우시려는 분들이 많은것같습니다. 오늘은 R과 R스튜디오를 매우 간단히 설치하는 방법을 알려드리려고 합니다. 먼저, R을 설치한후 R Studio를 설치하시면 됩
sunwoo-725.tistory.com
1. 패키치 설치 및 로드
install.packages("ggplot2") #패키지 설치
library(ggplot2) #패키지 로드2. 데이터 구조 확인
ggplot2 라이브러리에서 제공하는 mpg 데이터를 확인해봅시다.
head(mpg) #데이터 뒷부분은 tail()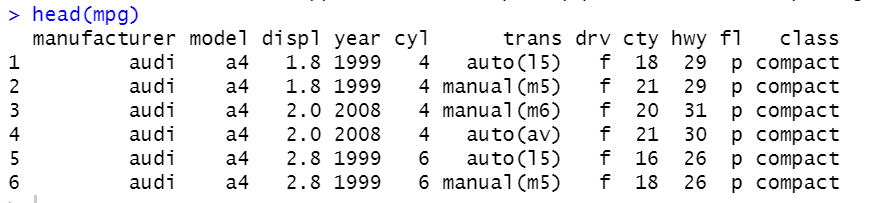
dim(mpg)
str(mpg) #데이터 속성
summary(mpg) #요약 통계량
View(mpg) #대문자V
qplot(data=mpg, y=hwy, x=drv, geom="point") #geom=point | boxplot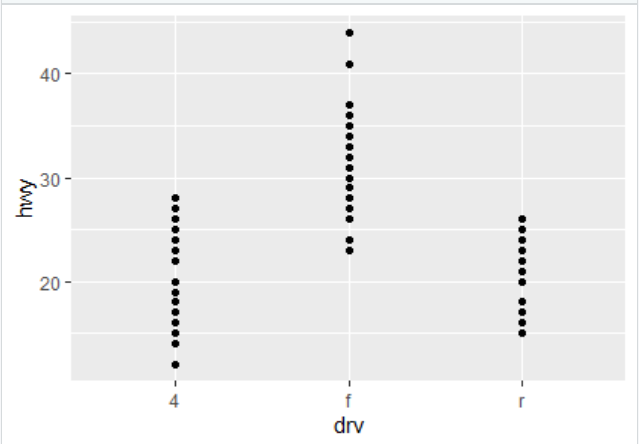
3. 함수
mean(mpg$hwy) #평균
max(mpg$hwy) #최댓값
hist(mpg$hwy) #히스토그램
mean() #평균
sd() #표준편차
sum() #합계
median() #중앙값
min() #최솟값
max() #최댓값
n() #빈도 ?qplot #사용법
4. 데이터 프레임 다루기
df_midterm <- data.frame(history = c(90, 80, 60, 70),
math = c(50, 60, 100, 20),
class = c(1, 1, 2, 2))
df_midterm
5. 데이터 R로 가져오기
install.packages("readxl")
library(readxl)
df_finalexam <- read_excel("finalexam.xlsx", sheet = 1, col_names = T)
df_finalexam6. 변수 관련
df_new <- rename(df_new, v2 = var2) # var2를 v2로 수정mpg$total <- (mpg$cty + mpg$hwy)/2 # 통합 연비 변수 생성exam %>%
mutate(total = math + english + science, # 합계 변수 추가
mean = (math + english + science)/3) # 평균 변수 추가7. 조건 함수
mpg$test <- ifelse(mpg$total >= 20, "pass", "fail") #20이상이면 pass, 아니면 fail
mpg$grade2 <- ifelse(mpg$total >= 30, "A",
ifelse(mpg$total >= 25, "B",
ifelse(mpg$total >= 20, "C", "D")))exam %>%
mutate(test = ifelse(science >= 60, "pass", "fail"))8. 빈도 확인
table(mpg$test) # 빈도표 출력
qplot(mpg$test) # 막대 그래프 생성9. 데이터 추출하기(Row-행)
exam %>% filter(class == 1) #class가 1인 경우만 추출하여 출력
#%>% 단축키:[Ctrl+Shift+M]exam %>% filter(class %in% c(1, 3, 5)) #class 1,3,5 추출10. 데이터 추출하기(Column-열)
exam %>% select(math)
exam %>% select(class, math, english)
exam %>% select(-math) # math 제외※Filter()와 select()를 조합하여 원하는 행, 열 추출하기
# class가 1인 행에서 english 열 추출
exam %>% filter(class == 1) %>% select(english)exam %>%
select(id, math) %>% # id, math 추출
head(10) # 앞부분 10행까지 추출 #%>% 여러번 이어쓰기 가능11. 데이터 정렬하기
exam %>% arrange(math) #오름차순
exam %>% arrange(desc(math)) #내림차순12. 집단별 group_by()
exam %>%
group_by(class) %>% # class별로 분리
summarise(mean_math = mean(math), # 수학 점수 평균
sum_math = sum(math), # 수학 점수 합계
median_math = median(math), # 수학 점수 중앙값
n = n()) # 빈도 - 학생 수
300x250
반응형
'데이터분석 > R' 카테고리의 다른 글
| R 및 R studio 가장 쉬운 설치방법-[빅데이터,통계-R] (2) | 2020.12.28 |
|---|

댓글